I closely examined the timestreams of 101208_ob7 as I said I would
yesterday. Unfortunately, all I can do is describe the symptoms: the
first deconvolution model looks good, though it isn't quite as wide as
the true source (this should be OK; it is an iterative method, after
all). In the second iteration, though, the deconvolution model is even
smaller and lower amplitude... and it goes on like that.
Not deconvolving results in a healthy-looking clean map - pretty much
what you expect and want to see.
This implies that somehow removing an incomplete deconvolved model leads
to more of the source being included in the 'atmosphere' than would have
been included with no model subtraction at all. I'm not sure how this is
possible. In fact... I'm really quite sure that it is not.
The workaround is to only add positive changes to the model. This should
'definitely work' but may be non-convergent and assumes that the model
never has anything wrong with it at any iteration. I have demonstrated
that this works nicely for the two Uranus observations I tested on, but
now I have to run the gamut of tests.... the first (very obvious)
problem is that the background is now positive, which is dead wrong.
This workaround is not viable.
Alright, so what next? I've described the symptoms and that I think they
can't occur...
A closer look shows that new_astro is not being incorporated into
astro_model at the second iteration. Why?
AHA! Pyflagger + find_all_points reveals the problem!
Map value: 16.939728 Weighted average: 17.476323 Unweighted Average: 524.573136
scan,bolo,time: mapped astro flags weight scale
3, 22, 12: 8.380408 13.561113 0.000000 0.025132 1.000000
4, 124, 23: 822.005327 13.561113 0.000000 0.000038 1.118012
4, 21, 38: 719.408983 13.561113 0.000000 0.000037 0.946721
5, 20, 7: 4.470616 13.561113 0.000000 0.013303 1.400000
5, 119, 23: 882.508303 13.561113 0.000000 0.000033 0.926887
5, 100, 35: 327.007750 13.561113 0.000000 0.000074 1.184397
5, 106, 38: 162.562098 13.561113 0.000000 0.000704 0.970000
6, 116, 27: 779.075640 13.561113 0.000000 0.000033 0.891768
8, 112, 3: 235.557390 13.561113 0.000000 0.000147 0.947130
9, 3, 14: 966.721773 13.561113 0.000000 0.000032 1.166292
9, 109, 41: 139.753656 13.561113 0.000000 0.000753 1.075269
10, 104, 8: 641.121935 13.561113 0.000000 0.000050 0.927827
10, 105, 24: 4.323228 13.561113 0.000000 0.032759 0.019022
10, 32, 36: 847.646990 13.561113 0.000000 0.000034 1.099406
11, 36, 9: 834.757586 13.561113 0.000000 0.000038 1.184751
11, 76, 37: 566.851891 13.561113 0.000000 0.000040 1.111000
12, 77, 13: 834.603090 13.561113 0.000000 0.000034 1.128464
12, 44, 44: 335.465654 13.561113 0.000000 0.000195 2.165775
13, 26, 17: 50.423143 13.561113 0.000000 0.004826 0.829932
13, 75, 29: 724.884676 13.561113 0.000000 0.000042 0.923077
14, 49, 21: 797.618990 13.561113 0.000000 0.000038 1.091918
14, 29, 33: 743.856012 13.561113 0.000000 0.000035 1.050360
15, 33, 13: 660.670099 13.561113 0.000000 0.000031 0.832180
15, 53, 25: 604.174286 13.561113 0.000000 0.000047 0.889922
15, 88, 40: 4.626476 13.561113 0.000000 0.008241 0.191489
17, 64, 20: 778.950533 13.561113 0.000000 0.000037 1.233108
18, 68, 30: 686.048136 13.561113 0.000000 0.000040 1.387283
Note that the lowest points have the highest weights. They DEFINITELY
shouldn't. What's wrong with them?
Apparently they have NO sensitivity to the sky! What?! There were a
bunch of bad bolos in Dec2010 that weren't flagged out... I wonder if
that problem persists to other epochs. Still, why does it only affect
pointing observations? Looking at the power spectra... the
large-timescale stuff becomes less dominant when scans are longer, but
the noisy spectra are still clearly noise-only. How odd.
Dropped to 112 good bolos from 134. That is much more believable. Have
to go back and fix Dec09 data too...
Even after fixing the bad bolos, the model drops with iteration number.
Why why why?
Well, looking at deconv_map, I've always returned the truly deconvolved
version, not the reconvolved... maybe the reconvolved really is better?
Again, this will have to be extensively tested, but it certainly gets
rid of the obvious/dominant error that the model kept dropping off.
However, FINALLY, based on how ridiculously good the reconv-deconvolved
map looks, I think I'm ready to do the extensive pipeline tests. So,
10dec_caltest has been started up with all of the new bolo_params
applied and the changes in place to deconv_map... let's see what
happens.
After that runs, I'll have to re-run the fit_and_plot routines











































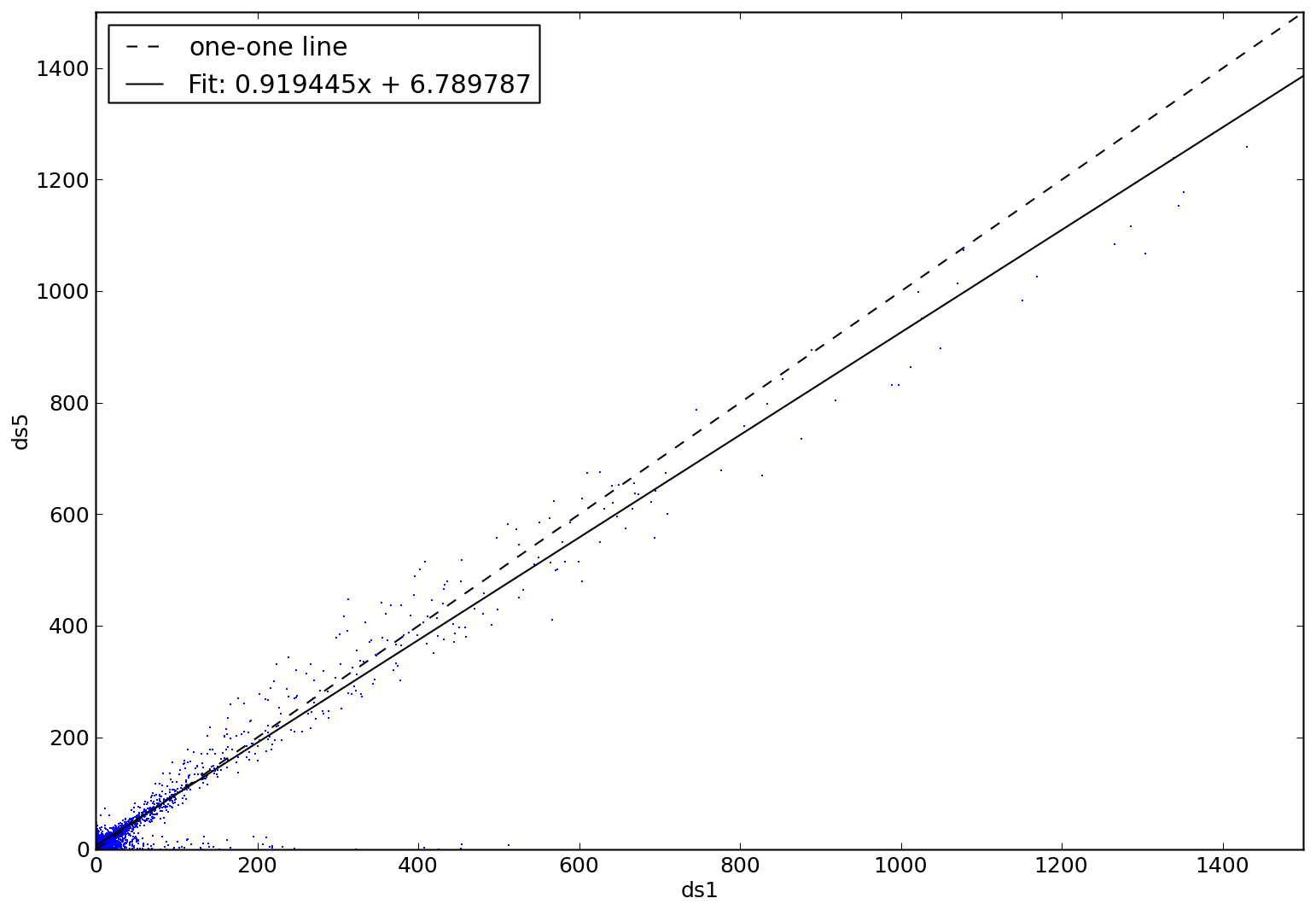{kind=link}